

Intent Detection is a vital part of the Natural Language Understanding (NLU) pipeline of Task-oriented dialogue systems. Recent advances in NLP have enabled systems that perform quite well on existing intent detection benchmarking datasets like HWU64, CLINC150, BANKING77 as shown in Larson et al., 2019, Casanueva et al., 2020. However, most existing datasets for intent detection are generated using crowdsourcing services. This difference in dataset preparation methodology leads to assumptions about training data which are no longer valid in the real world. In the real world, definition of intent often varies across users, tasks and domains.
Perception of intent could range from a generic abstraction such as “Ordering a product” to extreme granularity such as “Enquiring for a discount on a specific product if ordered using a specific card”. Additionally, factors such as imbalanced data distribution in the training set, diverse background of domain experts involved in defining the classes makes this task more challenging. During inference, these systems may be deployed to users with diverse cultural backgrounds who might frame their queries differently even when communicating in the same language. Furthermore, during inference, apart from correctly identifying in-scope queries, the system is expected to accurately reject out-of-scope queries, adding on to the challenge.
|
Dataset |
Domain |
Number of Intents |
Number of Queries |
|||
|
Train |
Test |
|||||
|
Full |
Subset |
In Scope |
Out of Scope |
|||
|
SOFMattress |
Mattress products retail |
21 |
328 |
180 |
231 |
166 |
|
Curekart |
Fitness supplements retail |
28 |
600 |
413 |
452 |
539 |
|
Powerplay11 |
Online gaming |
59 |
471 |
261 |
275 |
708 |
HINT3 Datasets and its statistics
Hence, to accurately benchmark in real-world settings, we release 3 new single domain datasets, each spanning multiple coarse and fine grain intents, with the test sets being drawn entirely from actual user queries on the live systems at scale instead of being crowd-sourced. On these datasets, we find that the performance of existing systems saturates at unsatisfactory levels because they end up capturing spurious patterns from the training data. Similar failures have been reported in computer vision also when Google’s medical AI was super accurate in lab but in real life it was a different story.
Few examples of queries from our dataset which failed on all platforms are shown in the table given below:
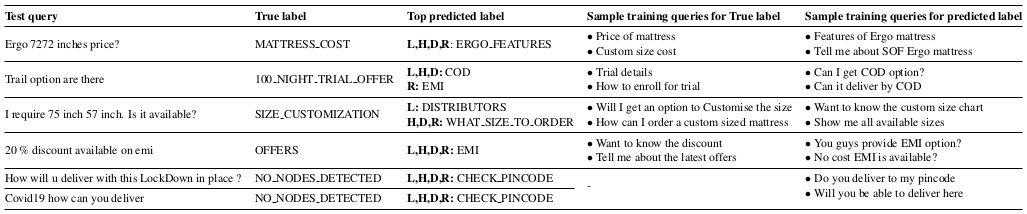
This figure shows few examples of test queries in SOFMattress which failed on all platforms, L: LUIS, H: Haptik, D:
Dialogflow, R: Rasa. NO NODES DETECTED is the out-of-scope label.
There are 3 major contributions based on our paper:
- We open-source 3 new datasets to accurately benchmark intent detection performance of task oriented dialogue systems in the real world.
- We evaluate 4 NLU platforms: Dialogflow, LUIS, Rasa NLU and Haptik on HINT3, highlight gaps in language understanding and discuss tradeoffs between performance on in-scope vs out-of-scope queries.
- We propose a novel 'subset approach' for evaluation by extracting one representative sample for each natural 'class' of examples based on mutual entailment scores.

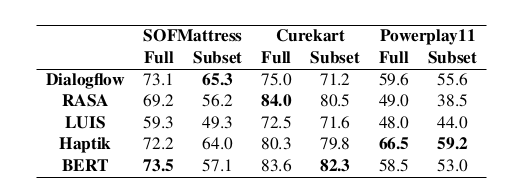
This figure presents results for all systems, for both Full and Subset variations of the dataset. Best Accuracy on all the datasets is in the early 70s. Best MCC (Matthew’s Correlation Coefficient) for the datasets varies from 0.4 to 0.6, suggesting the systems are far from perfectly understanding natural language.
In this table, we consider in-scope accuracy at a very low threshold of 0.1, to see if false positives on out-of-scope queries would not have mattered, what’s the maximum in-scope accuracy that current systems are able to achieve. Our results show that even with such a low threshold, the maximum in-scope accuracy which systems are able to achieve on Full Training set is pretty low, unlike the 90+ in-scope accuracies of these systems which have been reported on other public intent detection benchmarking datasets like HWU64, CLINC150, BANKING77 as shown in Larson et al., 2019, Casanueva et al., 2020.
We’ve made our datasets and code freely accessible on GitHub to promote transparency and reproducibility. You can also check out our paper "HINT3: Raising the bar for Intent Detection in the Wild" accepted at EMNLP-2020's Insights workshop for more details.





















.png?quality=low&width=352&name=BLOG-IMAGE-2022-FEB%20(1).png)






















.webp?width=352&name=Charles-Proxy%20(1).webp)


























source on Google