Immediate response is what everyone expects from their personal assistant and so are expectations of Haptik users. In order to scale with exponentially growing user base while providing consistent and quick service, Haptik significantly relies on machine learning and natural language processing.
I joined Haptik in January 2016 as a Machine Learning Scientist after completing masters from IIIT Hyderabad.
Haptik so far was built using NLP techniques like parts of speech tagging, stemming, lemmatization, etc.
Following rule based modules were already in place to set up the basic framework of automation.
- Preprocessing – It normalizes text data and has to be perfect for efficient functioning of other modules.
- Task Identification – This module interprets the user query and identifies what service user is exactly asking for.
- Entity Recognition – It identifies all the relevant details required from structured or unstructured data to get a particular task done from user.
- Response Generation – This module generates a natural language response either to collect user data, recommend different options or complete a transaction.
There was a limitation of efficiency and scalability due to rule based or supervised nature of algorithms in place which ultimately were limited by data. But today, Haptik has a large database of messages exchanged between users and assistants collected over last two years containing chats spreading across diversified domains like restaurant reservations, shopping, travel, etc. Database is rich in terms of features like domain, entities, user details, timestamps and core messaging text. Hence we were ready to take a next step and shift our algorithms to statistical and unsupervised systems.
Having core framework in place and access to rich database, advancements in deep learning and dialogue processing enabled us to create a completely unsupervised model which can predict responses by learning messaging sequence from existing data. Following is the list of some research work which was useful while building a learning model.
- A Neural Network Approach to Context-Sensitive Generation of Conversational Responses (response generation system that can be trained end to end on large quantities of unstructured Twitter conversations)
- A Diversity-Promoting Objective Function for Neural Conversation Models (Maximum Mutual Information (MMI) as the objective function in neural models)
- Neural Responding Machine for Short-Text Conversation
- A Neural Conversational Model (uses sequence to sequence framework)
After studying through multiple research papers, understanding existing automation architecture and considering the availability of tools and data, we came up with the new approach and named it ‘Sequence Learning for Personal Assistant’.
Concept of Sequence Learning
We observed that, a typical conversation between a user and an assistant follows a sequence of messages specific to every domain. In general, what we have seen, is a conversations may start with greeting or casual message (Ex. Hi, good morning!) followed by the actual task that needs to be done and then the next couple of messages are exchanged to get all the required information(Example: date, time, destination, delivery location). Finally we need to send a confirmation once the task is completed which may get followed by an acknowledgement or greeting from the user. We concluded that messages exchanged for every domain could be divided into finite number of meaningful clusters and every conversation could be represented by sequence of cluster ids. With thousands of conversations happening on daily basis, at Haptik we had millions of sequences to learn from and an accurate model to predict the next cluster in the ongoing sequence was generated.
Following is the overview of sequence learning where every message type represents a different cluster.
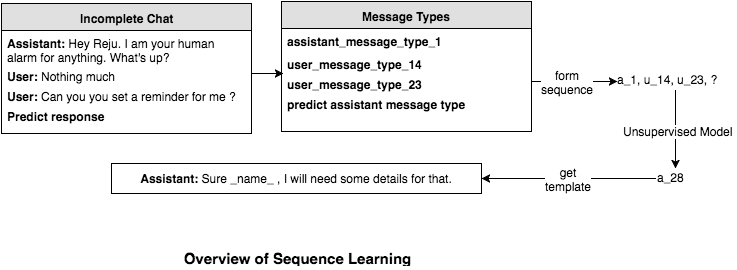
Training Specifications
- Figuring out all possible message types/clusters is a tedious task. To tackle this problem we identified all message types automatically by clustering the messages.
- For training sequence learning model, we used chat data from Haptik’s database. We identified and tagged each message in the database with appropriate message type and created a millions of sequence of message types for particular domain. Post sequence generation we treated it like a next word prediction problem using language model. We used RNNLM toolkit and SRILM toolkit for training a language model using combination of neural network and statistical approach to predict next cluster in the sequence.
We started off by putting sequence learning in production for one domain to validate our approach and it has revealed very positive results. As a next step, we will be expanding this approach for all the domains for getting things done for Haptik users in fastest and convenient way.
Wish to be a part of the amazing things we build? Look no further! Reach out to us at hello@haptik.co
P.S. – A big ‘Thank You’ to Dan Roth for his inputs on this algorithm.
This post is written by Aniruddha Tammewar, Machine Learning Scientist at Haptik.