

Imagine you're in a new city, and ask a passerby for directions to your destination. "Oh yes, I know where you want to go. Continue straight, turn left at the coffee shop, and it’ll be on your right," they confidently respond. The directions are conveyed with such certainty that you don’t question them.
However, after following the directions, you’re nowhere near where you should be. The person genuinely thought they knew the location, but their brain filled in the gaps of their actual knowledge with assumptions, leading to inaccurate information.
Hallucinations in large language models (LLM), also known as confabulations, have a similar effect.
Explained: How to Craft Effective Prompts for Enhanced LLM Responses
What are LLM Hallucinations?
Hallucinations are false or misleading information generated by an LLM that is not based on factual data or real-world context. The phenomenon is caused by insufficient, incorrect or biased training data, and the model’s assumptions of what words, phrases, or concepts should come next in a conversation or a response. When faced with gaps in knowledge or uncertain data, LLMs may attempt to fill in the blanks by generating plausible-sounding but ultimately incorrect information.
Unlike humans, AI models lack the self-awareness to recognize when they don't have sufficient information and avoid making things up. So they produce seemingly-logical outputs based on training data, even if the result is factually inaccurate or entirely made up.
How to Reduce Hallucinations in LLM
Here are five practical strategies to minimize LLM hallucinations, and ensuring the information is both accurate and relevant.
Executive's Guide: AI Agents: Reimagining the Breadth of Automation
Semantic and full-text search
Semantic and full-text search are powerful methods used in tandem to ensure that when information is pulled for an answer, it’s both accurate and relevant. Semantic search focuses on understanding the underlying meaning behind the words. On the other hand, full-text search scans for exact matches in the content. Through the combination of these approaches, LLMs are able to deliver meaningful information while ensuring the response directly addresses the question at hand and nothing important is overlooked.

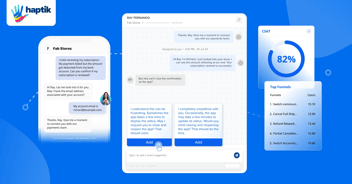
Response of LLM with semantic search for the input prompt
Imagine a user asking an LLM about the health benefits of green tea. A semantic search might understand that the user is looking for health-related information and retrieve data that discusses antioxidants, metabolism, and heart health.
.webp?width=900&height=555&name=best_practices_to_reduce_hallucinations_in_llm_2%20(1).webp)
Response of LLM with full-text search
A full-text search, however, would find specific mentions of "green tea benefits" in articles and extract exact phrases that match the query. Combining both methods ensures the response not only addresses the specific question but also provides rich contextual information.
Simple input prompts
Lengthy or overly complex prompts increase the cognitive load on the model, often resulting in inaccurate or irrelevant responses. To counter this, tasks can be broken down into smaller, more manageable steps, a technique known as prompt chaining or chaining of prompts. By structuring prompts, each individual task becomes clearer and easier for the large language model to process, reducing confusion and resulting in more accurate and relevant outputs. The overall quality of the LLM’s responses is significantly improved too, making the system more reliable in delivering precise answers.
.webp?width=900&height=313&name=best_practices_to_reduce_hallucinations_in_llm_3%20(1).webp)
LLM provides a generic, superficial response for complex prompt
Instead of asking an LLM, “What are the benefits of exercise for health and how can one start a routine?”, which is complex, break it down into smaller prompts:
Prompt 1: “What are the benefits of exercise for health?”
.webp?width=900&height=687&name=best_practices_to_reduce_hallucinations_in_llm_4%20(1).webp)
Breaking down the prompt elicits a more comprehensive LLM response
Prompt 2: “What are some tips for starting an exercise routine?”
.webp?width=900&height=620&name=best_practices_to_reduce_hallucinations_in_llm_5%20(1).webp)
This method of structuring queries, prompts the LLM to generate more focused and accurate responses for each part of the query.
Constitution and guardrails
Without guardrails, LLMs are prone to filling in gaps by drawing on their vast knowledge, even when they lack the necessary context to provide accurate answers. This can lead to hallucinations or responses that seem plausible but are ultimately incorrect or irrelevant. By implementing guardrails or safeguards, we restrict the models from tapping into their pre-existing knowledge base and ensure they focus solely on the information provided in the current dataset or context. This targeted approach ensures that responses are highly accurate, contextually relevant, and aligned with the task at hand.
Improve performance with fine-tuning
.webp?width=900&height=547&name=best_practices_to_reduce_hallucinations_in_llm_6%20(1).webp)
The response of a non-fine-tuned LLM lacks specific examples and fewer details
Beyond reducing hallucinations, fine-tuning boosts the performance of large language models by aligning them more closely with specific tasks or datasets. It involves training the model on targeted, domain-specific data, which refines its understanding, accuracy, and ability to generate contextual responses. Fine-tuning boosts the model’s generalization, transfer learning, data requirements, and incurs lower training costs. Additionally, this technique makes LLMs both efficient and adaptable for a wide range of specialized applications, ensuring high performance without the need for extensive retraining from scratch. Additionally, organizing the input for clarity and enhanced logic alleviates GPT’s tendency to hallucinate.
For instance, consider a user asking, “What are the best practices for optimizing an online store for conversions?” A fine-tuned LLM would provide a tailored response that highlights key strategies relevant to eCommerce, such as a user-friendly design, incorporating high-quality images, streamlining the checkout process, and more.
Grounding in citations
Requesting citations enhances the reliability of responses generated by GPT models. When users request citations, the model is prompted to focus on pulling information directly from the source - reducing the likelihood of hallucinations or the model fabricating details. By grounding its responses in verifiable references, GPT can ensure that the information it delivers is not only accurate but also verifiable. Moreover, citations help contextualize the information for deep insights into the background and credibility of the content.
When a user asks for statistics on climate change, instead of just providing a statement like, “Climate change is increasing,” the LLM could respond with: “According to a 2023 report by the Intergovernmental Panel on Climate Change (IPCC), global temperatures have risen by 1.2°C since the pre-industrial era.” This grounding in a specific citation enhances the reliability of the information and allows users to verify the source, reducing the risk of hallucination.
Closing Thoughts
Reducing hallucinations in LLMs is not only key to improving accuracy, but also ensuring that businesses can make data-driven decisions without second-guessing the model’s responses. Unreliable AI or LLM-generated outputs can lead to costly mistakes, reduced customer trust, or misalignment with business goals. Reducing hallucinations safeguards the integrity of the insights that businesses rely on to drive meaningful outcomes.
At Haptik, our expert GenAI consultants specialize in refining language models so they deliver precise and contextually-relevant outputs every time. Our expertise allows us to handle the technical complexity of the model’s performance while you focus on growing your operations and delivering value to customers.
Related: [Download] The CXO's Guide to Enterprise Gen AI Adoption















source on Google